Deville systematic
Introduction
The Deville systematic design is a sampling method developed in 1998 by Jean-Claude Deville. While it shares similarities with systematic sampling, it has distinct properties. Chauvet (2012) demonstrated that Deville systematic sampling and the ordered pivotal method are actually the same underlying sampling design.
This vignette explains how to use the functions sys_deville and sys_devillepi2 and includes a small simulation to verify that the second-order inclusion probabilities align with those calculated by the function spm from the BalancedSampling package, which implements the ordered pivotal method.
Generating Data
Inclusion probabilities are generated unequally and are proportional to a random uniform variable.
library(sampling)
library(StratifiedSampling)
library(BalancedSampling)set.seed(1)
N <- 20
n <- 3
pik <- inclusionprobabilities(runif(N),n)Simulations
To verify whether the function correctly computes second-order inclusion probabilities, we perform a large number of simulations to estimate the second-order inclusion probability matrix.
SIM <- 100000
PI_1 <- PI_2 <- matrix(rep(0,N*N),ncol = N,nrow = N)
for(i in 1:SIM){
s1 <- BalancedSampling::spm(pik)
s1_01 <- rep(0,N)
s1_01[s1] <- 1
s2 <- sys_deville(pik)
s2_01 <- rep(0,N)
s2_01[s2] <- 1
PI_1 <- PI_1 + s1_01%*%t(s1_01)
PI_2 <- PI_2 + s2_01%*%t(s2_01)
}
PI_1 <- PI_1/SIM
PI_2 <- PI_2/SIMExact matrix of second order inclusion
The function sys_devillepi2 computes the exact second order inclusion probabilities.
PI <- sys_devillepi2(pik) # compute the second order inclusion probabilitiesResults
We visualize and compare the second-order inclusion probability matrices.
PI_1_sp <- as(as.matrix(PI_1),"sparseMatrix")
PI_2_sp <- as(as.matrix(PI_2),"sparseMatrix")
PI_sp <- as(as.matrix(PI),"sparseMatrix")
image(PI_1_sp)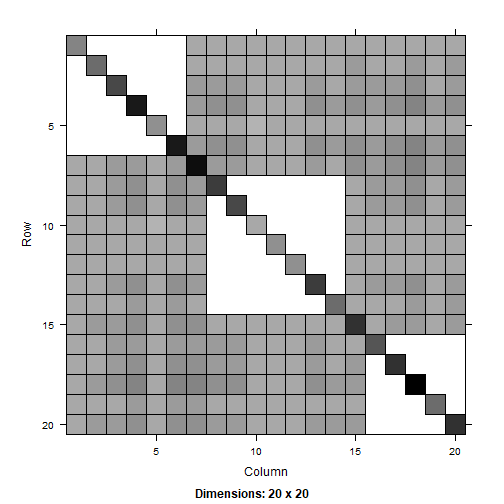
image(PI_2_sp)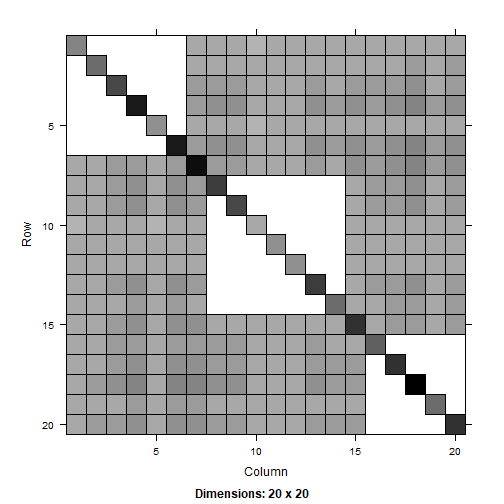
image(PI_sp)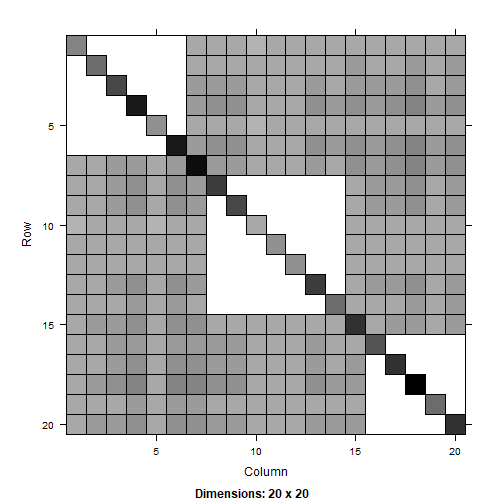
Accuracy test
To test accuracy, we verify that the estimated probabilities closely match the expected values.
# proportional test, these values should be approximately to 0.95
length( which(abs((PI_1_sp@x - PI_sp@x)/sqrt(PI_sp@x*(1-PI_sp@x)/SIM)) < 1.96))/length(PI_sp@x)#> [1] 0.961039length( which(abs((PI_2_sp@x - PI_sp@x)/sqrt(PI_sp@x*(1-PI_sp@x)/SIM)) < 1.96))/length(PI_sp@x)#> [1] 0.9448052References
Chauvet, G. (2012), On a characterization of ordered pivotal sampling, Bernoulli, 18(4):1320-1340 DOI: https://doi.org/10.3150/11-BEJ380