The Deville systematic design is a sampling method developed in 1998 by Jean-Claude Deville. While it shares similarities with systematic sampling, it has distinct properties. Chauvet (2012) demonstrated that Deville systematic sampling and the ordered pivotal method are actually the same underlying sampling design.
This vignette explains how to use the functions sys_deville and sys_devillepi2 and includes a small simulation to verify that the second-order inclusion probabilities align with those calculated by the function spm from the BalancedSampling package, which implements the ordered pivotal method.
Generating Data
Inclusion probabilities are generated unequally and are proportional to a random uniform variable.
To verify whether the function correctly computes second-order inclusion probabilities, we perform a large number of simulations to estimate the second-order inclusion probability matrix.
To test accuracy, we verify that the estimated probabilities closely match the expected values.
# proportional test, these values should be approximately to 0.95length(which(abs((PI_1_sp@x-PI_sp@x)/sqrt(PI_sp@x*(1-PI_sp@x)/SIM))<1.96))/length(PI_sp@x)
Balanced sampling plays a crucial role in applied statistics. In this vignette, we explain how to use the balseq function to select a balanced and spatially distributed sample. For a detailed explanation of the method, refer to doi:10.1002/env.2776.
Loading Data
We will use the belgianmunicipalities dataset from the sampling package, which does not contain spatial coordinates. Fortunately, a GEOjson file is available on ArcGIS Hub. We transform it into an sf object and compute the municipalities’ centroids to distribute the sample across space.
# to load datalibrary(sampling)library(geojsonio)library(ggplot2)library(viridis)library(rgeos)library(sf)library(rmapshaper)data("belgianmunicipalities")# load geojson directly from the urlbelg<-geojson_read("https://opendata.arcgis.com/datasets/9589d9e5e5904f1ea8d245b54f51b4fd_0.geojson",what="sp")# simplify the variable and transform it into a sf objectbelg<-rmapshaper::ms_simplify(input=belg,keep=0.01)%>%st_as_sf()coord<-gCentroid(as(belg,"Spatial"),byid=TRUE)# concatenated fileBelgium<-cbind(belg,belgianmunicipalities,coord)head(Belgium)
A good sample should maintain the population’s characteristics. By defining proportional inclusion probabilities, we ensure better representativity. We set up here the inclusion probabilities equal with sum equal to 50. i.e. the sample will contain 50 units.
N<-nrow(Belgium)# population totaln<-50# sample size# variable of interesty<-belgianmunicipalities$averageincome# auxiliary variablesXaux<-cbind(belgianmunicipalities$Tot04,belgianmunicipalities$Women04,belgianmunicipalities$TaxableIncome,belgianmunicipalities$Diffmen,belgianmunicipalities$Diffwom)# inclusion probabilitiespik<-rep(n/N,N)Xaux<-cbind(pik,Xaux)# add pik to fixed sample sizeXspread<-coord
Balanced sampling
We compare balanced sampling balseq with two other methods: samplecube and simple random sampling srswor. The percentage deviation from auxiliary totals helps evaluate the balance quality.
To incorporate spatial distribution, we use geographic coordinates as a matrix to the argument Xspread of the function. Here coord is an output of the function gCentroid which is by construction an S4 object. To get the data.frame that are encapsulated inside, we simply use the @coords operator.
Geographical data are generally auto-correlated, making it preferable to avoid sampling neighboring units. We introduce a new method for selecting well-spread samples from a finite spatial population with equal or unequal inclusion probabilities. The proposed method, called wave (Weakly Associated Vectors), defines the contiguity structure using dense stratification. This method precisely satisfies inclusion probabilities while providing well-spread samples. This document serves as an introduction to using the wave() function.
Data Generation
We use the meuse dataset from the sp package, described as follows:
This dataset provides locations and topsoil heavy metal concentrations, along with various soil and landscape variables recorded at observation locations in a floodplain of the river Meuse, near Stein (NL).
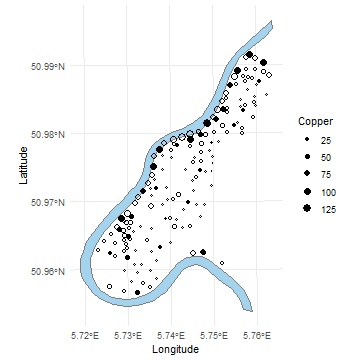
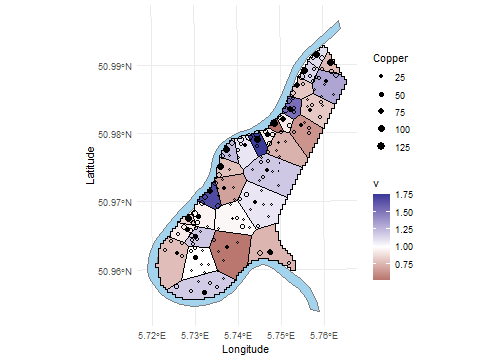
As explained by Grafström and Tillé (2013), we generate inclusion probabilities proportional to copper concentration, a highly spatially correlated variable.
where \(v_i\) is equal to the sum of the inclusion probabilities inside the \(i\)th polygons and \(\bf s\) is the vector of size \(N\) with elements equal 0 or 1. This quantity is implemented in the package BalancedSampling with the function sb(). We calculate the values of the \(v_k\) with the function sb_vk.
The closer \(B(\bf s)\) is to zero, the better is the spatial balance of the sample. Graphically, we obtain the following plot.
Another way to estimate the spatial spread is developed by Tillé et al. (2018), it uses a corrected version of the traditional Moran’s \(I\) index. This estimator use spatial weights \(w_{ij}\) that indicates how a unit \(i\) is close from the unit \(j\). Such matrix is supposed to include inclusion probabilities in its computation, hence, the spatial weights matrix \(\bf W\) is generally not symmetric. The spatial balance measure is given by
\[I_B =\frac{(\bf s-\bf \bar{s}_w)^\top \bf W (\bf s-\bf \bar{s}_w)}{\sqrt{(\bf s-\bf \bar{s}_w)^\top \bf D (\bf s-\bf \bar{s}_w) (\bf s-\bf \bar{s}_w)^\top \bf B (\bf s-\bf \bar{s}_w) }},\]
where \(\bf D\) is the diagonal matrix containing the \(w_i\),
\[\bf \bar{s}_w = \bf 1 \frac{\bf s^\top \bf W \bf 1}{\bf 1^\top \bf W \bf 1},\]
and
\[\bf B = \bf W^\top \bf D^{-1} \bf W - \frac{\bf W^\top \bf 1\bf 1^\top \bf W}{\bf1^\top \bf W \bf 1}.\]
The Moran’s \(I\) index is implemented in the function IB(). It is possible to specify your own spatial weights with the argument W. There is no natural way of defining \(\bf W\), here we propose to consider for each unit only the neighbour such that the sum of the inclusion probabilities of the stratum sum up to 1. It is implemented in the function wpik(). Another way of estimating the spatial weights is developed by Tillé et al. (2018) and use the inverse of the inclusion probabilities \(1/\pi_i\) to estimate the neighbours of the unit \(i\). It is implemented in the function wpikInv(). As explain by Tillé et al. (2018), \(w_{ii}\) is supposed to be equal to 0 for all \(i \in U\). By construction the function wpik does not return the diagonal equal to zero. So if we want to calculate the Moran’s I index with wpik, we need to subtract the diagonal of the returned matrix.
W<-wpik(X,pik)W<-W-diag(diag(W))IB(W,s)
#> [1] -0.4895601
W1<-wpikInv(X,pik)IB(W1,s)
#> [1] -0.4554427
References
Grafström, A., Lundström, N. L. P., and Schelin, L., (2012). Spatially balanced sampling through the pivotal method, Biometrics, 68(2):514-520
DOI: https://doi.org/10.1111/j.1541-0420.2011.01699.x
Grafström, A. and Tillé, Y., Doubly balanced spatial sampling with spreading and restitution of auxiliary totals, Environmetrics, 14(2):120-131
DOI: https://doi.org/10.1002/env.2194
Stevens Jr., D.L. and Olsen, A. R. (2004), Spatially balanced sampling of natural resources. Journal of the American Statistical Association, 99(465):262-278
DOI: https://doi.org/10.1198/016214504000000250)
Tillé, Y., Dickson, M. M., Espa, G., and Giuliani, D. (2018). Measuring the spatial balance of a sample: A new measure based on Moran’s I index, Spatial Statistics, 23:182-192
DOI: https://doi.org/10.1016/j.spasta.2018.02.001
]]>Raphaël JauslinStatistical Matching using Optimal Transport2021-10-19T00:00:00+00:002021-10-19T00:00:00+00:00https://rjauslin.github.io/ot-matchingIntroduction
In this vignette, we explore how key functions from the package can be used to estimate a contingency table. Our analysis is based on the eusilc dataset from the laeken package. Each function discussed here is thoroughly explained in the manuscript by Raphaël Jauslin and Yves Tillé (2021), available on doi:10.1016/j.jspi.2022.12.003.
Contingency Table
To construct the contingency table, we examine the factor variable pl030, which represents economic status, in combination with a discretized version of the equivalized household income, eqIncome. The discretization process involves calculating specific percentiles (0.15, 0.30, 0.45, 0.60, 0.75, 0.90) of eqIncome and defining categorical intervals based on these values.
data("eusilc")eusilc<-na.omit(eusilc)N<-nrow(eusilc)# Xm are the matching variables and id are identity of the unitsXm<-eusilc[,c("hsize","db040","age","rb090","pb220a")]Xmcat<-do.call(cbind,apply(Xm[,c(2,4,5)],MARGIN=2,FUN=disjunctive))Xm<-cbind(Xmcat,Xm[,-c(2,4,5)])id<-eusilc$rb030# categorial income splitted by the percentilec_income<-eusilc$eqIncomeq<-quantile(eusilc$eqIncome,probs=seq(0,1,0.15))c_income[which(eusilc$eqIncome<=q[2])]<-"(0,15]"c_income[which(q[2]<eusilc$eqIncome&eusilc$eqIncome<=q[3])]<-"(15,30]"c_income[which(q[3]<eusilc$eqIncome&eusilc$eqIncome<=q[4])]<-"(30,45]"c_income[which(q[4]<eusilc$eqIncome&eusilc$eqIncome<=q[5])]<-"(45,60]"c_income[which(q[5]<eusilc$eqIncome&eusilc$eqIncome<=q[6])]<-"(60,75]"c_income[which(q[6]<eusilc$eqIncome&eusilc$eqIncome<=q[7])]<-"(75,90]"c_income[which(eusilc$eqIncome>q[7])]<-"(90,100]"# variable of interestsY<-data.frame(ecostat=eusilc$pl030)Z<-data.frame(c_income=c_income)# put same rownamesrownames(Xm)<-rownames(Y)<-rownames(Z)<-idYZ<-table(cbind(Y,Z))addmargins(YZ)
Here we set up the sampling designs and define all the quantities we will need for the rest of the vignette. The sample is selected with simple random sampling without replacement and the weights are equal to the inverse of the inclusion probabilities.
# size of samplen1<-1000n2<-500# sampless1<-srswor(n1,N)s2<-srswor(n2,N)# extract matching unitsX1<-Xm[s1==1,]X2<-Xm[s2==1,]# extract variable of interestY1<-data.frame(Y[s1==1,])colnames(Y1)<-colnames(Y)Z2<-as.data.frame(Z[s2==1,])colnames(Z2)<-colnames(Z)# extract correct identitiesid1<-id[s1==1]id2<-id[s2==1]# put correct rownamesrownames(Y1)<-id1rownames(Z2)<-id2# here weights are inverse of inclusion probabilitiesd1<-rep(N/n1,n1)d2<-rep(N/n2,n2)# disjunctive formY_dis<-sampling::disjunctive(as.matrix(Y))Z_dis<-sampling::disjunctive(as.matrix(Z))Y1_dis<-Y_dis[s1==1,]Z2_dis<-Z_dis[s2==1,]
Harmonization
Then the harmonization step must be performed. The harmonize function returns the harmonized weights. If the true population totals are known, it is possible to use these instead of the estimate made within the function.
re<-harmonize(X1,d1,id1,X2,d2,id2)# if we want to use the population totals to harmonize we can use re<-harmonize(X1,d1,id1,X2,d2,id2,totals=c(N,colSums(Xm)))w1<-re$w1w2<-re$w2colSums(Xm)
The statistical matching is done by using the otmatch function. The estimation of the contingency table is calculated by extracting the id1 units (respectively id2 units) and by using the function tapply with the correct weights.
# Optimal transport matchingobject<-otmatch(X1,id1,X2,id2,w1,w2)head(object[,1:3])
Y1_ot<-cbind(X1[as.character(object$id1),],y=Y1[as.character(object$id1),])Z2_ot<-cbind(X2[as.character(object$id2),],z=Z2[as.character(object$id2),])YZ_ot<-tapply(object$weight,list(Y1_ot$y,Z2_ot$z),sum)# transform NA into 0YZ_ot[is.na(YZ_ot)]<-0# resultround(addmargins(YZ_ot),3)
As you can see from the previous section, the optimal transport results generally do not have a one-to-one match, meaning that for every unit in sample 1, we have more than one unit with weights not equal to 0 in sample 2. The bsmatch function creates a one-to-one match by selecting a balanced stratified sampling to obtain a data.frame where each unit in sample 1 has only one imputed unit from sample 2.
# With Z2 as auxiliary information for stratified balanced sampling.BS<-bsmatch(object,Z2)Y1_bs<-cbind(X1[as.character(BS$object$id1),],y=Y1[as.character(BS$object$id1),])Z2_bs<-cbind(X2[as.character(BS$object$id2),],z=Z2[as.character(BS$object$id2),])YZ_bs<-tapply(BS$object$weight/BS$q,list(Y1_bs$y,Z2_bs$z),sum)YZ_bs[is.na(YZ_bs)]<-0round(addmargins(YZ_bs),3)
# split the weight by id1q_l<-split(object$weight,f=object$id1)# normalize in each id1q_l<-lapply(q_l,function(x){x/sum(x)})q<-as.numeric(do.call(c,q_l))Z_pred<-t(q*disjunctive(object$id1))%*%disjunctive(Z2[as.character(object$id2),])colnames(Z_pred)<-levels(factor(Z2$c_income))head(Z_pred)